

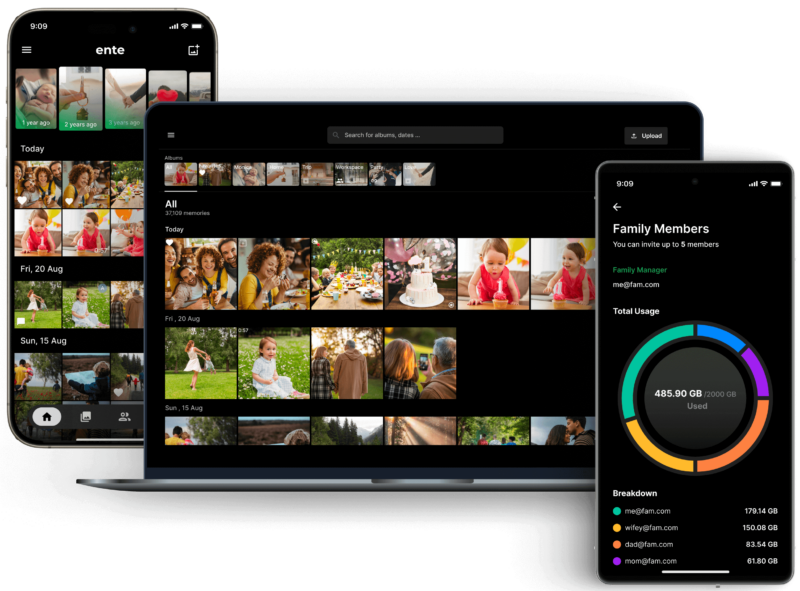
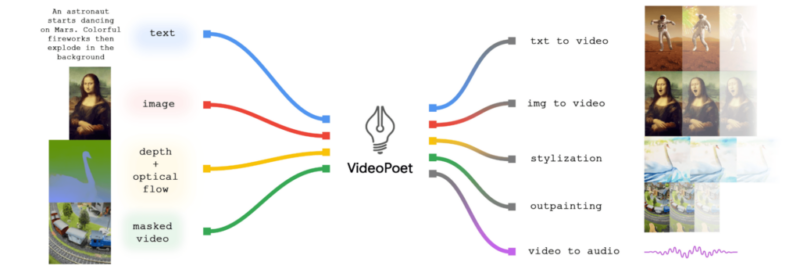
谷歌宣布推出新的语音语言模型“AudioPaLM”。该模型是语音技术领域的创新者,具备前所未有的精度,可以听、说和翻译。它是一种多模态架构,将文本和语音结合在一起,可以用于处理语音识别和音频翻译等应用。它继承了PaLM-2模型的语言知识和AudioLM模型的语音特征,可以保持说话者的同一性和声调等语音信息。
什么是 AudioPaLM?
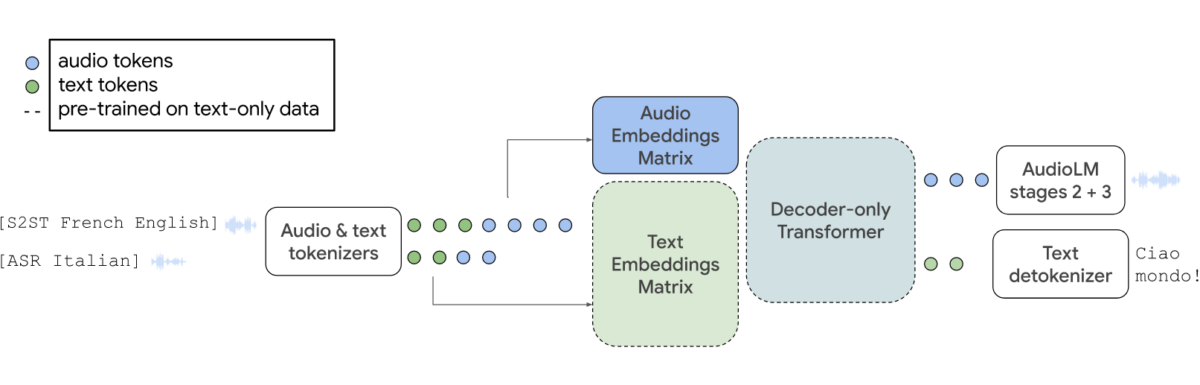
AudioPaLM是由谷歌研究团队开发的大规模语言模型,能够处理语音理解和生成的任务。AudioPaLM将现有的PaLM 2模型和AudioLM模型的优点结合起来,产生了一种统一的多模态架构,可以处理并生成文本和语音。这使得AudioPaLM能够处理各种应用程序,从语音识别到语音文本转换。
AudioLM在保持说话者身份和语调等非语言信息方面表现出色。而PaLM 2则是基于文本的语言模型,专注于文本特定的语言知识。通过结合这两个模型,AudioPaLM可以利用PaLM 2的语言专业知识和AudioLM的非语言信息保持能力,更深入地理解和生成文本和语音。
![图片[1] - 谷歌推出新语音语言模型 AudioPaLM:具备前所未有的精确度、听、说和翻译的能力 - EVLIT](https://imgcache.evlit.com/wp-content/uploads/2023/06/WX20230625-210412-1200x385.png)
AudioPaLM 的特点
AudioPaLM是一种新型大规模语言模型,可以以前所未有的精度听、说和翻译。它使用了通用词汇来表示语音和文本,使用这个通用词汇和标记任务的描述相结合,使得单个解码器的模型可以训练用于处理多样的语音和文本任务。这使得以前需要使用不同模型处理的语音识别、文本到语音合成、语音到语音翻译等任务可以在单个架构和训练过程中统一处理。
评估结果表明,AudioPaLM在音频翻译方面表现出了比现有系统更好的性能。它还展示了零样本语音文本翻译的能力,可以准确地将以前从未遇到过的语言的音频翻译为文本。这为更广泛的语言支持提供了可能性。此外,AudioPaLM还可以基于短音频提示在语言之间传输声音,并捕捉并再现不同语言中独特的声音。这使得语音转换和适应成为可能。
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。















![表情[xiaojiujie] - EVLIT](https://cdn.evlit.com/wp-content/themes/zibll/img/smilies/xiaojiujie.gif)
暂无评论内容