

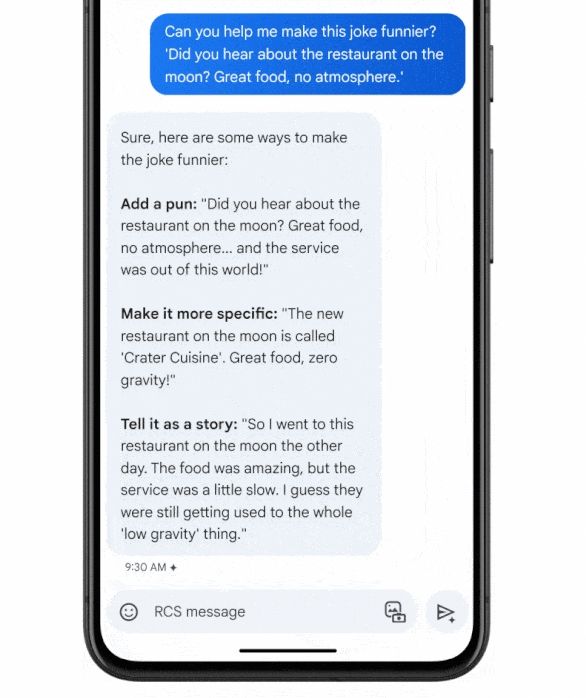
谷歌最近宣布其最新的视频创作人工智能模型:Lumiere,这是一种新的 AI 模型,可以从文本提示生成高质量视频,也允许用户提供源图像(但不验证该图像的真实性)作为参考,并以此作为目标样式生成视频。与传统的 T2V 模型不同,该模型能够一次生成整个视频序列,从而实现更加一致且逼真的动作。
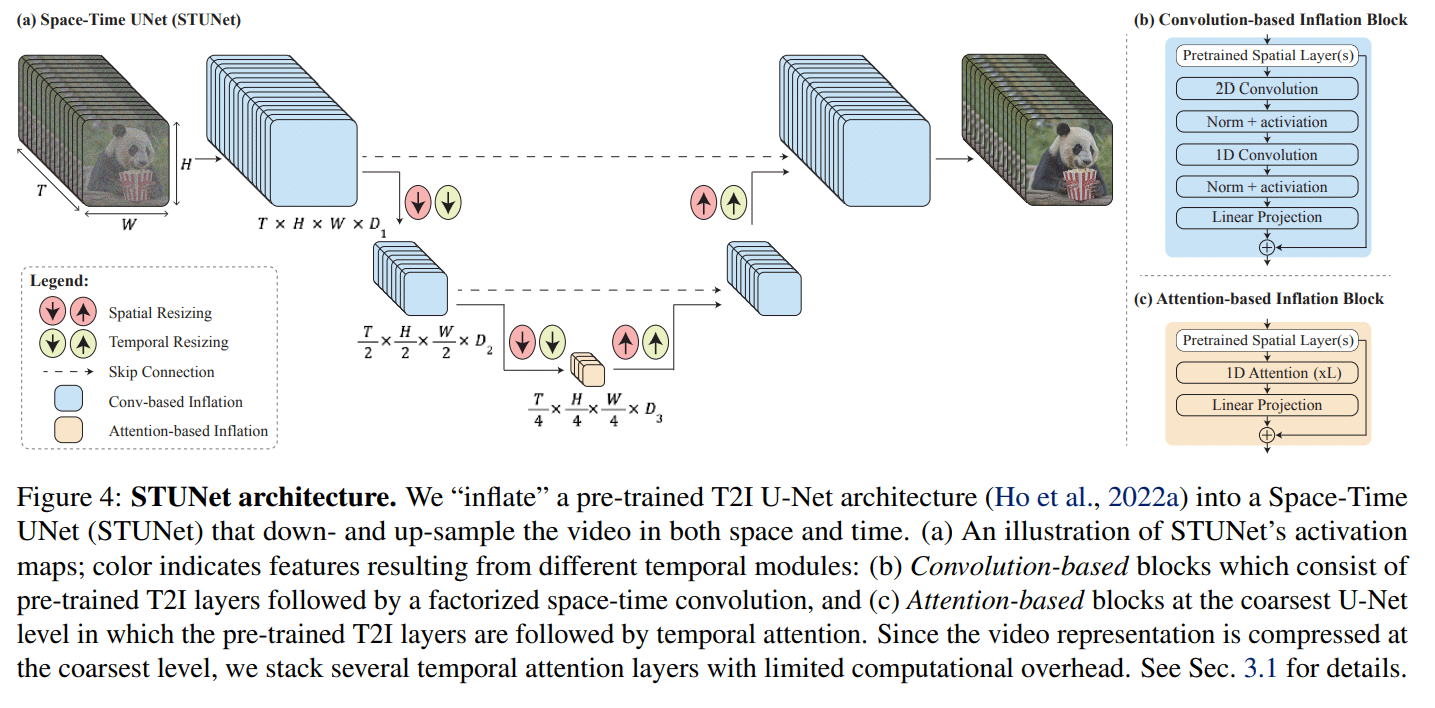
Lumiere 依赖于空间和时间下采样和上采样。首先,它会生成关键帧,然后使用时间超分辨率 (TSR) 模型来插入关键帧之间缺失的帧。与传统的 T2V 模型不同,后者会先对视频序列进行下采样,然后再次进行上采样,而 Lumiere 能够一次生成整个视频序列。这使得它能够在整个视频中实现更加一致且逼真的动作。

这是通过 STUNet 架构实现的,该架构不仅会像现有方法那样对空间分辨率进行下采样然后再进行上采样,还会对时间分辨率进行上采样。视频的每秒帧数会先被下采样,然后再次被上采样。通过下采样,模型会以较低的帧数来处理视频,但仍然可以看到视频的全部内容。这样,模型就可以学习到在这种较低的帧数下,对象和场景是如何移动和变化的。
Lumiere 还可用于其他应用程序,例如视频修复、图像到视频生成和风格化视频。该模型通过 3000 万个视频学习,在视频质量和文本匹配方面,与其他方法相比,显示出具有竞争力的结果。该模型通过具有相关文本标题的 3000 万个视频学习。视频长度为 80 帧,每秒 16 帧 (fps),每个视频有 5 秒。该模型基于预先训练的冻结文本-图像模型,并通过与视频相关的方面(例如时间维度)的附加层进行扩展。
一旦模型学习了这种缩小分辨率下的基本运动模式,它就可以以此为基础来提高最终视频在完整时间分辨率下的质量。这个过程可以提高生成动作和场景的质量,同时还可以更有效地处理视频。
一旦视频以这种较低的时间和空间分辨率生成后,Lumiere 就会使用多重扩散进行空间超分辨率 (SSR)。这包括将视频分割成重叠的片段,然后逐个增强每个片段以提高分辨率。然后,这些片段会被拼接在一起,从而创建出一致的高分辨率视频。这个过程可以制作出高质量的视频,而无需直接制作高分辨率视频所需的庞大资源。
Lumiere 是从文本生成视频的 AI 模型中最新且功能最强大的模型之一。该模型有望在电影、电视、游戏、广告等各个领域得到应用。但是,该模型也存在被滥用以创建虚假或有害内容的风险,因此需要采取措施来确保其安全和公平使用。
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。















![表情[xiaojiujie] - EVLIT](https://cdn.evlit.com/wp-content/themes/zibll/img/smilies/xiaojiujie.gif)
暂无评论内容