

OpenAI 出品的最新神经网络模型DALL-E 3,为我们打开了图像生成技术的新篇章。该模型继承了其前任DALL-E 2的独特优势,并且在许多方面实现了突破性的提升,除了生成比其前身更高质量的图像之外,OpenAI 的 DALL-E 3 还有一项重大改进,即:”它能够更准确地理解用户输入提示并输出适当的图像。‘。
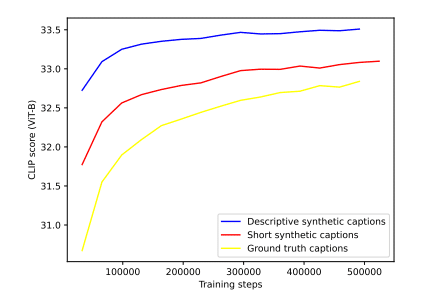
研读他们已经发表的一篇关于 DALL-E 3 的论文:“Improving Image Generation with Better Captions“,我们了解到DALL-E 3在图像生成领域的一大创新之处就在于它具有高质量的理解能力,这在很大程度上应归功于其结合了机器和人类的注释方式。“95%的注释是由机器完成,5%的则由人类完成。”看似微小的比例,却提供了人类的思考逻辑与机器冷酷精确的结合。
为了证明该模型的精准度,OpenAI对DALL-E 3进行了一系列详尽的合成基准测试以及由人类进行的评估。在DALL-E3实际训练之前,OpenAI训练了自己的AI图像校准器,并将其用于实际DALL-E3图像系统训练用图像数据的重新标注。
![图片[1] - AI 图像生成的新篇章 – OpenAI 的 DALL-E 3 - EVLIT](https://imgcache.evlit.com/wp-content/uploads/2023/10/deb298176fb2fe4257669868d0edbe27.png)
即使是简短的合成注释,在基准上也大大超过了人类的注释。较长的描述性注释得到了更好的结果,因此是否可以得出一个结论:越高比例的机器注释,意味着越好的图像生成效果。
为了让大家更为直观地理解,我们可以拿其与前一代模型DALL-E 2以及业内另外一款知名的人工智能模型Midjourney5.2与Stable Diffusion XL进行比较。在所有的合成基准测试中,DALL-E 3几乎在所有案例中都大幅跑赢了它们。OpenAI的图像AI在风格和一致性这一点上稍好于Midjourney5.2,但开源的图像AI Stable Diffusion XL则落后更多一些。
然而OpenAI同样诚实地提到,DALL-E 3在空间物体定位上还存在一些问题,比如当要识别图片中物体的左、右、后等位置信息时,还有待进一步提升。
那些整日头痛因为要挑选照片而苦恼的设计师们,或许在不久的将来,可以将更多时间花在启发思维、创造艺术上。科技以人为本,而前所未有的需求又进一步推动了科技的进步。此次DALL-E 3的发布,无疑为了图像生成技术绘制了一个全新的蓝图,我们期待在未来可以看到更多更好的应用。
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。

















![表情[xiaojiujie] - EVLIT](https://cdn.evlit.com/wp-content/themes/zibll/img/smilies/xiaojiujie.gif)
暂无评论内容