

当微软和Google为谁的人工智能聊天机器人更好而使出浑身解数时,我们不难发现这并不是机器学习和语言模型的唯一用途。除了传闻中计划在今年的年度Google
I/O活动中展示20多种由人工智能驱动的产品外,Google正在朝着建立一个支持1000种不同语言的人工智能语言模型的目标迈进。
在周一发布的更新中,Google分享了有关通用语音模型(USM)的更多信息,Google称这一系统是实现其目标的”关键第一步”。
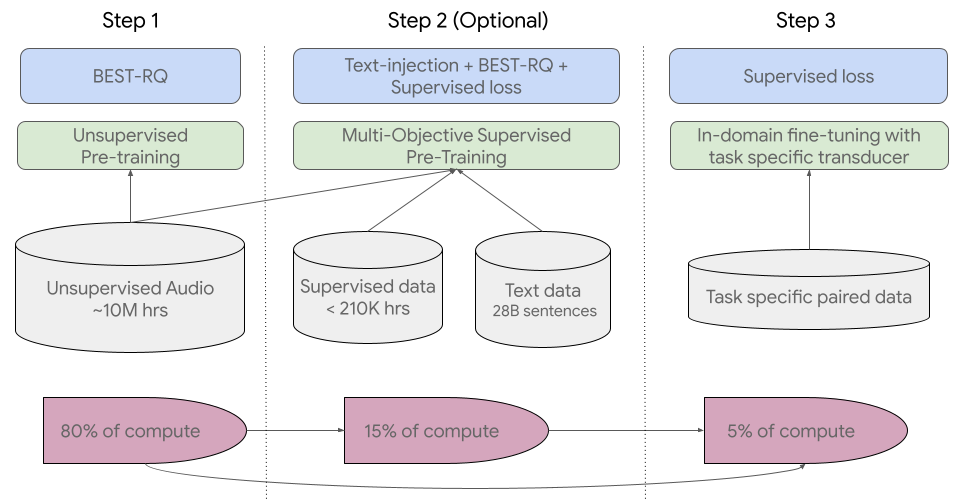
去年11月,该公司宣布其计划创建一个支持全球1000种最常用语言的语言模型,同时还披露了其USM模型。Google将USM描述为”一个最先进的语音模型系列”,它有20亿个参数,在1200万小时的语音和超过300种语言的280亿个句子中进行训练。
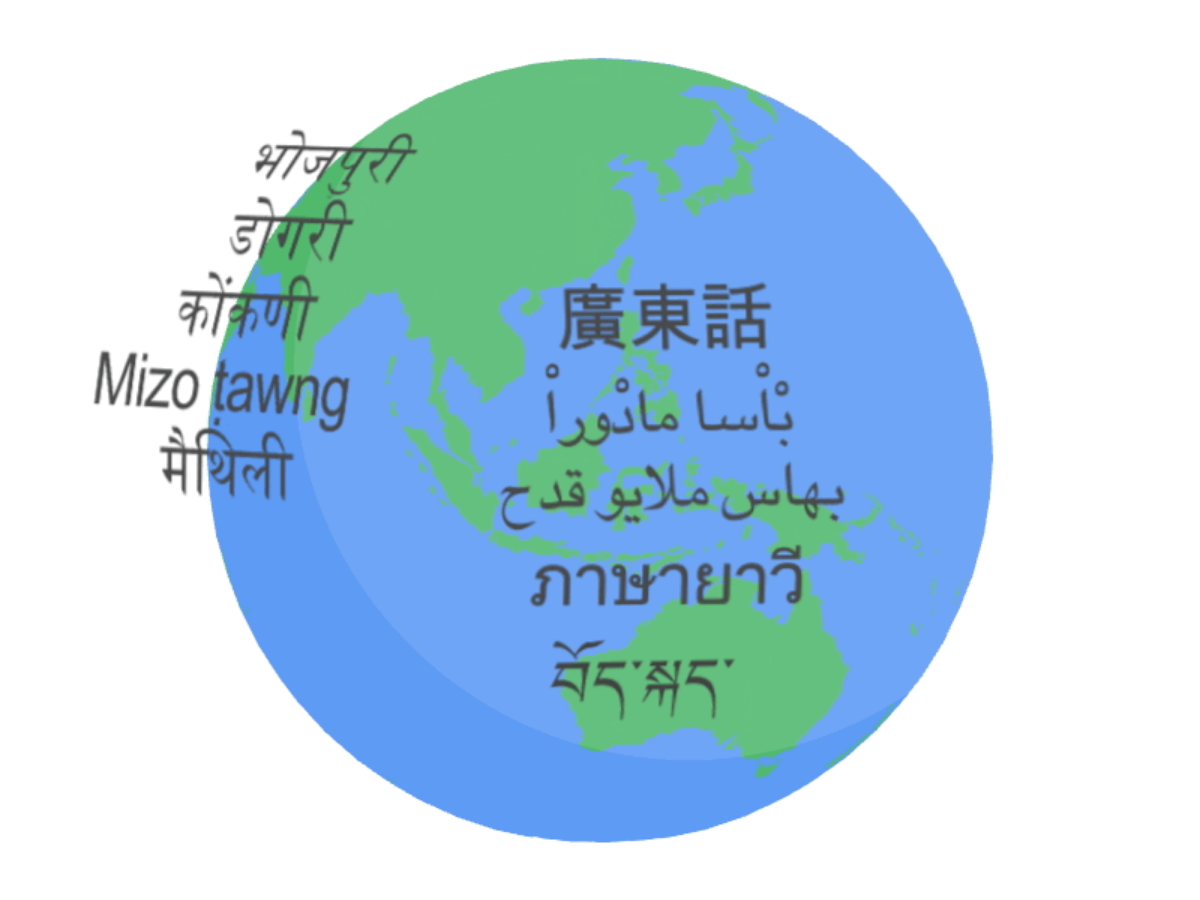
YouTube已经使用USM来生成封闭式字幕,它还支持自动语音识别(ASR),这可以自动检测和翻译语言,包括英语、中文普通话、阿姆哈拉语、宿务语、阿萨姆语等等。
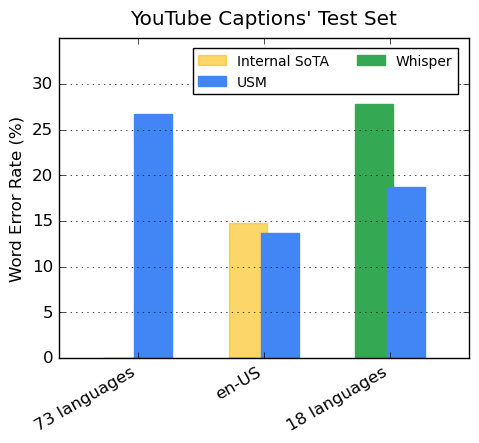
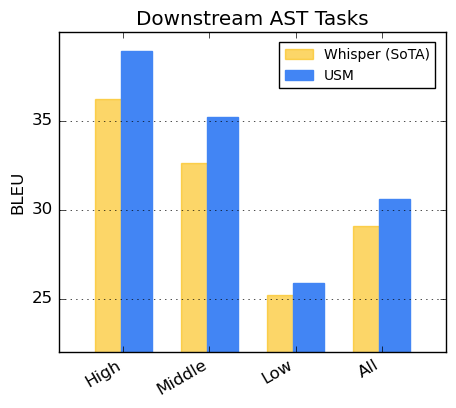
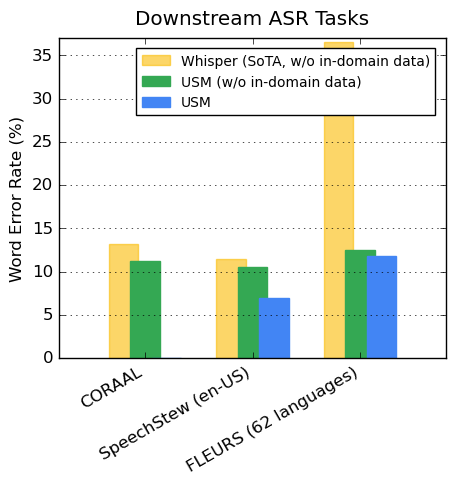
现在,Google USM支持超过100种语言,并将作为”基础”来建立一个更加广泛的系统。与此同时,Meta公司正在开发一个类似的人工智能翻译工具,但目前仍处于早期阶段。
您可以在Google发布的研究论文中阅读更多关于USM和它如何工作的信息:
https://arxiv.org/abs/2303.01037
该技术的一个目标可能是在增强现实的眼镜内,就像Google去年在I/O活动中展示的概念一样,能够检测并提供实时翻译,不过,这项技术似乎还有点遥远,Google在I/O大会期间对阿拉伯语的错误表述证明了它是多么容易出错。
原文链接: Google离建立其1000种语言的人工智能模型又近了一步 – Google 谷歌 – cnBeta.COM
© 版权声明
本站所有文章,仅代表文章作者个人观点,如对观点有疑义时不用怀疑,您绝对是对的。
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。
您也可以联系文章作者本人进行修改,若内容侵权或非法,可以联系我们进行处理。
任何个人或组织,转载、发布本站文章到任何网站、书籍等各类媒体平台,必须在文末署名文章出处并链接到本站相应文章的URL地址。
本站文章如转载自其他网站,会在文末署名原文出处及原文URL的跳转链接,如有遗漏,烦请告知修正。
如若本站文章侵犯了原著者的合法权益,亦可联系我们进行处理。
THE END








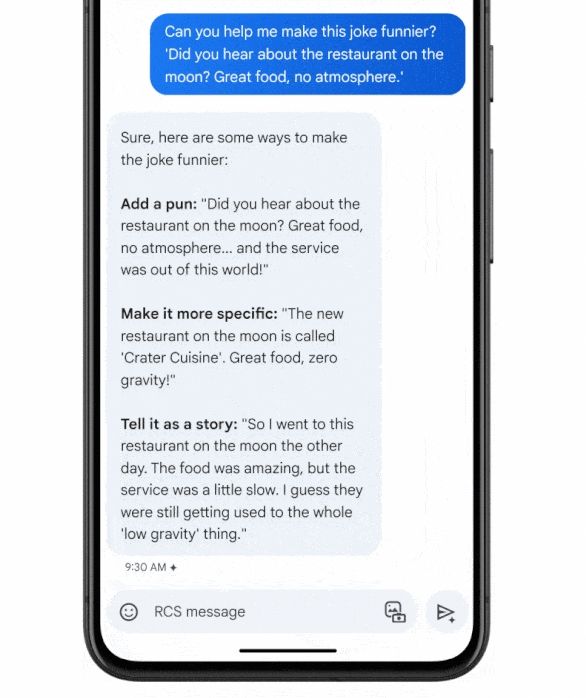







你好16小时前0
你好,可以再帮我看看吗? 我已经按照你的方法设定了,还是一样,wordpress后台的 Purge Varnish Cache 插件还是清除不到cache,依旧显示 the varnish control terminal is not responding at。谢谢 https://mjj.today/i/Srk2Tz https://mjj.today/i/Srkcoi你好3天前0
对,你说的没错,我配置的时候改了一些东西,现在我按照你的教学,可以启动了,网页可以缓存了,不过wordpress 清除cache 那个插件没用的,我输入本地回环地址127.0.0.1 :6082 ,再输入API key ,插件显示the varnish control terminal is not responding at 127.0.0.1:6082,就你图片那样,然后试一下点击清除cache 那里,他显示error,研究了一天,还是没有不行。你好4天前1
你好,为啥我按照你的方法,到第三部分,去到真正后源的服务器设定Varnish 部分,我填了真正后源的IP跟端口跟域名,然后重启 Varnish ,就出现这样了? 这是怎么回事? 谢谢 [Linux] AMH 7.1 https://amh.sh [varnish-6.6 start] ================================================== =========== [OK] varnish-6.6 is already installed. Could not delete 'vcl_boot.1713549650.959259/vgc.sym': No such file or directory Error: Message from VCC-compiler: VCL version declaration missing Update your VCL to Version 4 syntax, and add vcl 4.1; on the first line of the VCL files. ('/home/usrdata/varnish/default.conf' Line 1 Pos 1) ... #--- Running VCC-compiler failed, exited with 2 VCL compilation failedchu17天前0
很完善的教程‘hu22天前0
我用gmail EMAIL_SERVER="smtp://********@gmail.com:bpyfv*********[email protected]:587"叽喳22天前0
MAIL_SERVER="smtp://[email protected]:[email protected]:587" 大佬 这个使用outlook 或者gmail 是什么样子的格式? 邮寄已经开启smtp了hu22天前0
输入框的问题解决了,我没有设置反代,NEXTAUTH_URL改为域名+端口就好了hu22天前0
后面搭好了,但是不配置umami的话,进去之后保存按钮点不了,而且转发设置了都不通 又重新搭之后注册界面输入框没了